Impression of Claude Opus 4.5
This is a personal perspective view of model, it might be biased so you should try it yourself for your own use case.
Recently, Anthropic released a new “best model in the world for coding, agents, and computer use” - code name Opus 4.5.
I’ve been a huge fan of Anthropic since they released 3.5 Sonnet v1 back in June 2024. It’s been over a year and I still love the anthropic family model. However, in the past couple of months with the releases of GPT-5 Codex, GPT-5.1, and Grok 4.1 Fast, Claude had become my secondary choice and no longer my daily driver due to pricing, mediocre performance and server down.
With this new Claude Opus 4.5, I… still haven’t fully switched back, bruh Claude still slow asf compare to other provider? But for some complex tasks and other aspect, my experience has definitely changed.
I’ve been up for a day testing this new model since they released it through the Bedrock Foundation Model API (AWS). Thank you to “my company” for paying all the token expenses - hopefully they won’t figure out, hehe
Speed and Pricing
From what’s immediately noticeable, comparing to the previous version of Opus, the new Opus 4.5 is much faster in token generation speed (~60 t/s compared to ~40 t/s from the previous version). The pricing is also 3x lower: $5/$25 per 1M input/output tokens compared to $15/$75 previously. Crazy value pull from Anthropic.
New Tool Calling Techniques
Anthropic also introduced some new techniques for tool calling like search tool and programmatic tool calling. I remember programmatic tool calling was first experimented with in the smolagents library on GitHub. This is great for me since I can MCP tools without worrying about whether the model will degrade or sacrifice the context window.
My Setup
For testing, I used Claude Code and switched it to fully use Claude Opus 4.5. The default setting uses multiple models - probably Opus for planning, Sonnet for implementing and writing code, and Haiku for researching implementations online.
Performance
For backend tasks, it can one-shot pretty much everything very well. I’ll continue playing with this to have more updates and a better overview of the model’s performance, but it’s a great start for me.
I used this model to update this entire blog website’s frontend and data management structure for handling blog pages and upload sequences. Here’s the new updated output with a minimal, modern, dark material design vibe (I only ran one iteration since I was too lazy to keep iterating):
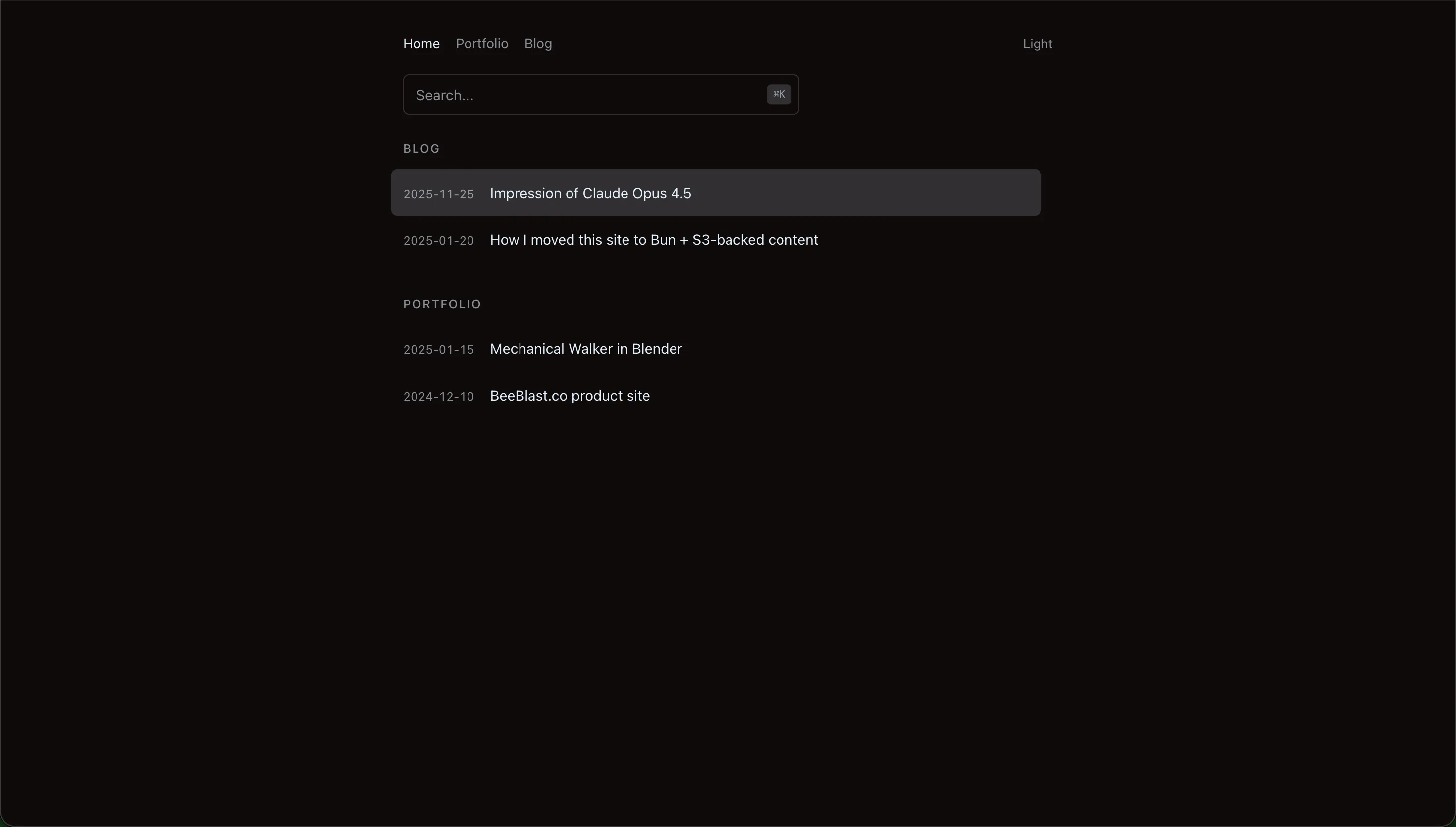 New home page: Clean layout with global search (⌘K shortcut), date-title rows, and subtle hover states
New home page: Clean layout with global search (⌘K shortcut), date-title rows, and subtle hover states
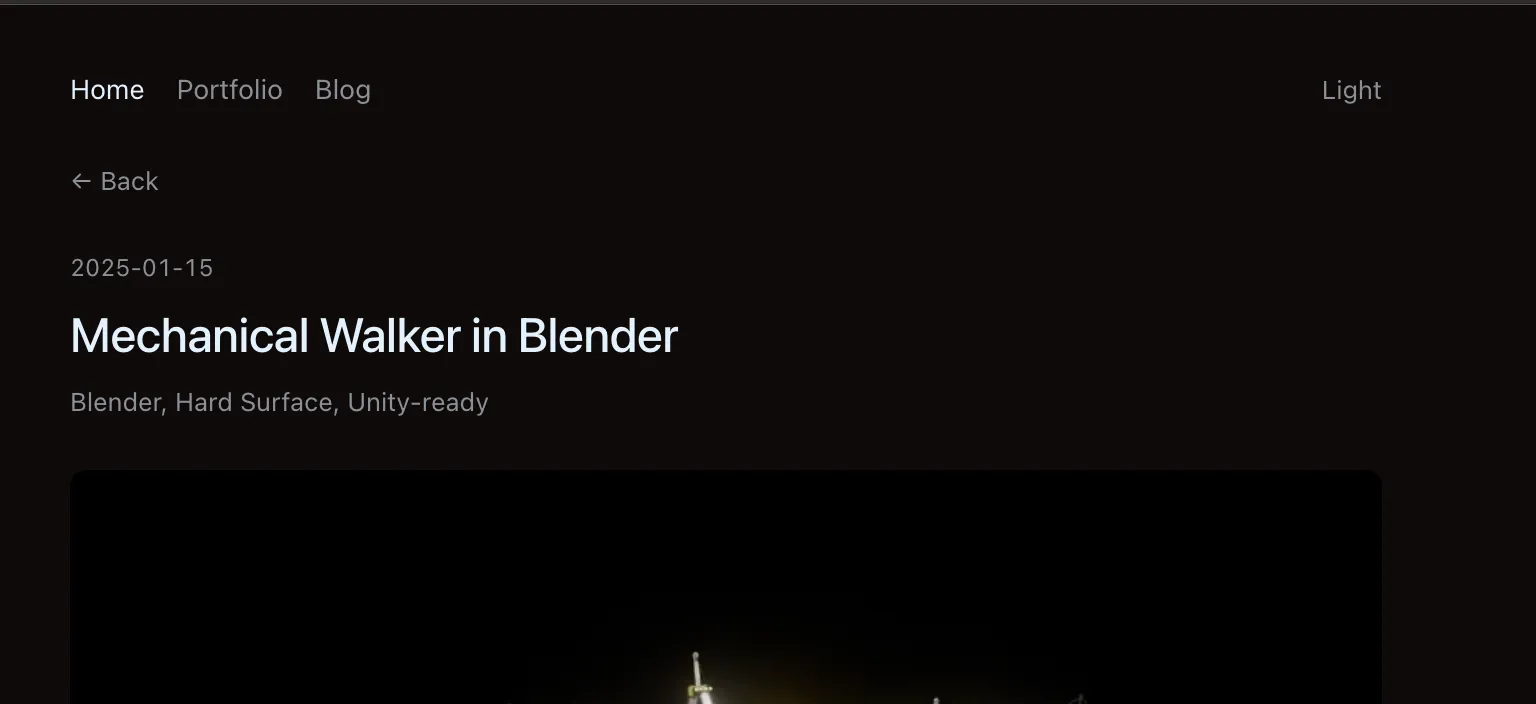 New detail view: Simplified header with meta tags and clean typography
New detail view: Simplified header with meta tags and clean typography
What the helly, this model is cap bro? Since GPT-5 dropped, I’ve been using the GPT model family for frontend iteration and coding, but now I might reconsider. Here’s the old website for comparison (you’re probably using the new one I updated with Claude Code right now):
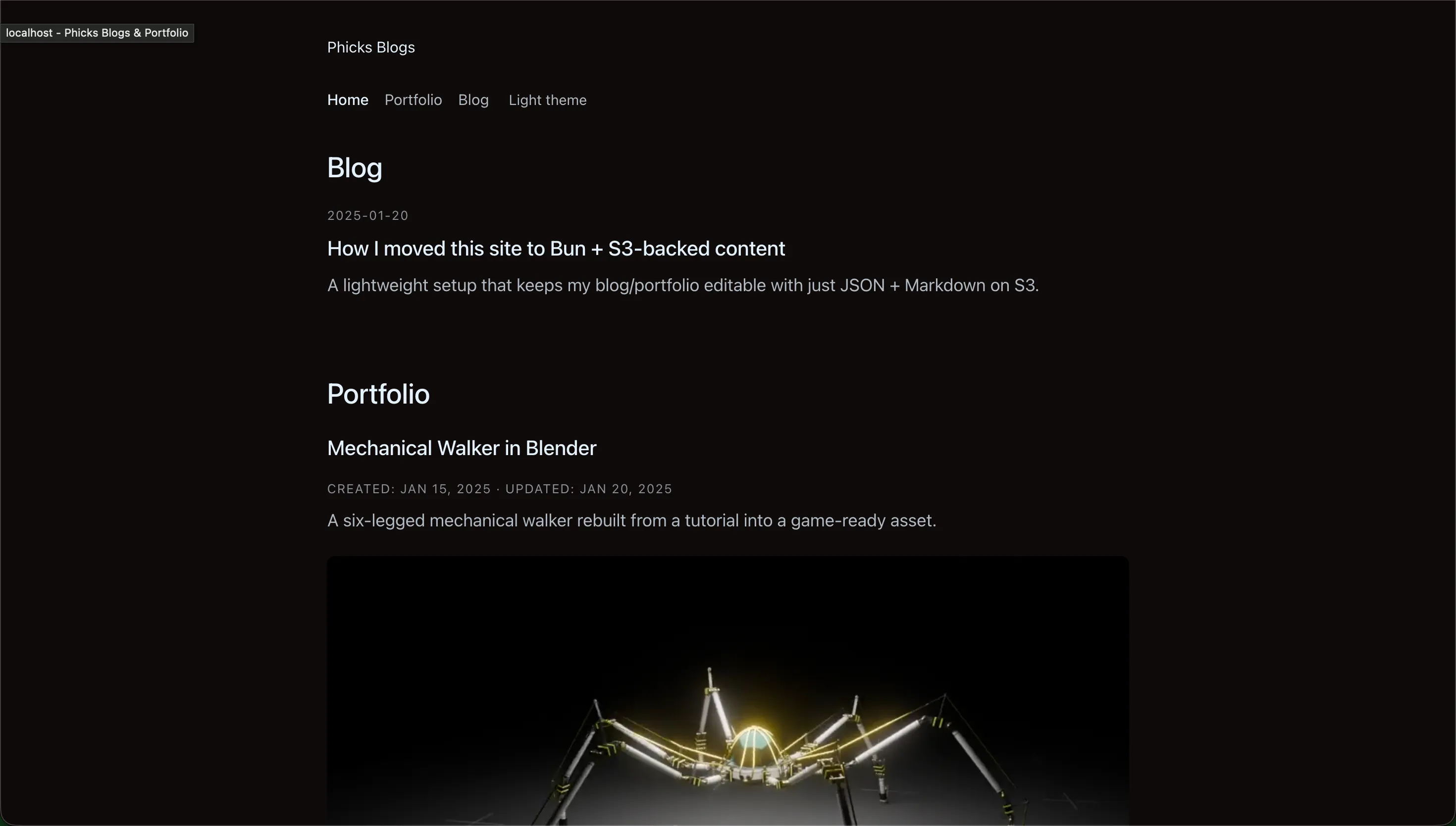 Old home page: Larger section headers, descriptions in list view, images embedded directly
Old home page: Larger section headers, descriptions in list view, images embedded directly
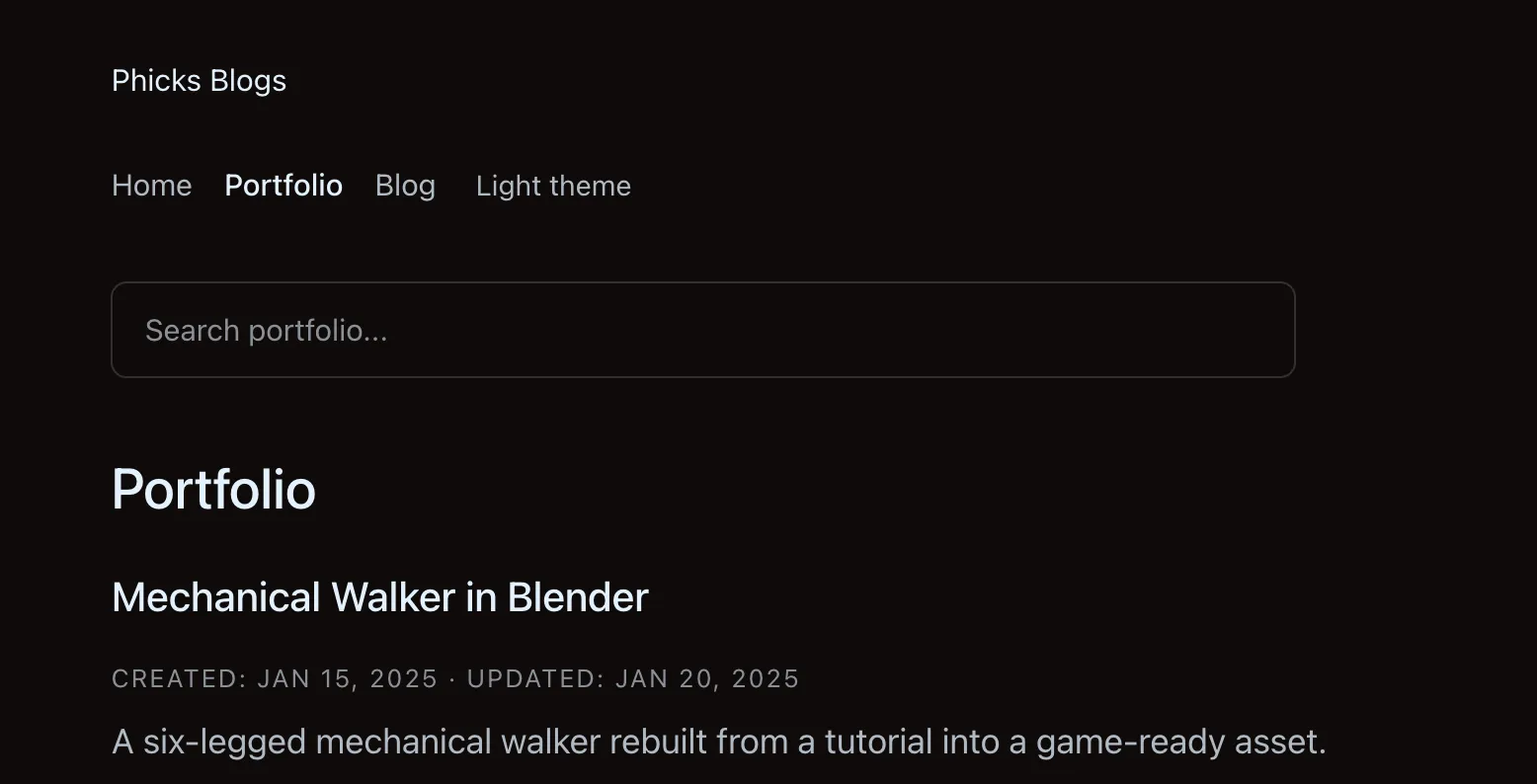 Old portfolio page: Verbose layout with full descriptions and metadata
Old portfolio page: Verbose layout with full descriptions and metadata
 Old detail view: Image captions and underlined action links
Old detail view: Image captions and underlined action links
Other Models Comparison
For transparency, I should also test other models (Gemini 3 Pro, GPT-5.1 Codex Max, Minimax M2, Grok 4.1, and Kimi K2 Thinking) for comparison.
I ran all of these one-shot only (I know it’s not completely fair since LLMs are non-deterministic), but I’m too lazy and don’t have much budget for extensive testing. So far, Opus 4.5 is still one of the best compared to the rest.
Library Updates
I also used the new Opus model to refactor and maintain the aiobedrock library to match Anthropic’s new advanced tool use features and improve security. Updates will be rolling out soon.
I’ll continue using this model as my main driver (thank you for paying the bill, my “beloved company”). Will update if anything new comes up or a new model drops.